
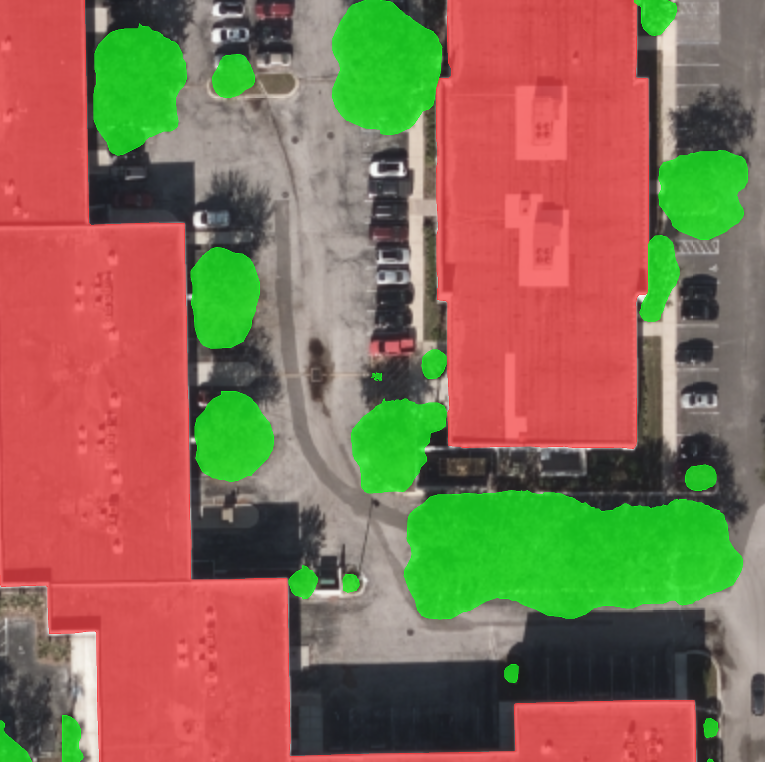
When we’re not working on hurricane or wildfire models—or, I guess, curling (full disclosure, contrary to what the job description claims, I've yet to go curling)—CrowdAI builds segmentation models to try to pick out static objects in full-motion video. One of these projects had a particularly frustrating quality.
After training for a while, our model would do well on the provided validation set. A few weeks down the line, when newly-labeled data was incorporated into the model, performance would fall sharply. Despite doing well on the validation set, our model didn’t actually generalize.

Reviewing the Data (The game is afoot)
After briefly considering whether I should just resign in shame (decided against it), we dug a little deeper into the data. A deeper visual analysis confirmed our nagging suspicion that the provided data had clips from the same videos appearing in both the train and validation sets. While not identical, these clips shared strong similarities: flying over similar regions or even what appeared to be the same area. Without a reliable validation set to lead us, our model was overfitting, explaining our poor performance on new data.
We were able to track down video metadata that helped us pair clips with individual flights. Turns out, previous data had pretty bad contamination between the train and val sets. We estimated if there were >10 clips for a flight, at least one clip would show up in both train and val. This is reflected in models doing well on our val set, but then initially performing poorly on the next data drop.
To assess the full extent of the contamination, I bucketed our flights into 3 groups. First, the worst offenders, ‘heavily contaminated’: examples of the flight were in both the train and val set or the clips were visually very similar. Next, we had ‘contaminated’: examples where there were clips in both train and val (note that heavy contamination is a subset of this group). Finally, uncontaminated cases: where a flight was solely in the validation set—the ideal. When we broke it down we saw the following.
PERCENTAGE OF VAL HEAVILY CONTAMINATED 0.36
PERCENTAGE OF VAL CONTAMINATED 0.59
PERCENTAGE OF VAL NOT CONTAMINATED 0.41Breaking down performance of our best model by contamination level, we see - unsurprisingly - that our scores are much worse on uncontaminated data than heavily contaminated data, a pixel level F1 drop of nearly 6.
PIXEL-LEVEL SCOREs NOT CONTAMINATED:
F1 0.839527106157721
PRECISION 0.8951125382720957
RECALL 0.7904416148438631
---
PIXEL CONTAMINATED:
F1 0.8641968577626662
PRECISION 0.8934060871525319
RECALL 0.8368371079256595
---
PIXEL HEAVILY CONTAMINATED:
F1 0.8968283416995237
PRECISION 0.9053792308787132
RECALL 0.8884374597334683Next Steps (What do we do!?!)
Luckily, ‘knowledge is half the battle’ (I think Descartes said this, but it might have been GI Joe). Once we diagnosed the issue, we were able to work with the customer to get a wider variety of flights and start taking measures to combat the contamination.
The results are striking (striking!), as you can see below. On the right, we have the old data before we raised the issue. As you can see, it has relatively few flights with tons of examples. Since these examples were assigned randomly to train and val, the more examples a flight has, the more likely it is to contaminate both sets. On the left, we see a drastic increase in the number of flights, and a left-shifting over the distribution. This means more diversity and less contamination!


In addition, we were able to do our own splitting of train/validation based on flight IDs and this yielded more robust estimates of our actual generalization and helped us avoid overfitting. After taking these steps, we’ve seen much more stable performance on our new data, implying that our model is beginning to truly generalize the way we hope! Truly a story book ending.
Lessons Learned (Narrativizing my pain)
In retrospect, maybe we should have prioritized running K-fold experiments earlier or ignored the validation splits we were given. But even then, we only had a handful of unique flights, so we may have been capped in those experiments by a limited diversity of data. While the contamination caused us to overestimate the generalization of the model and may have guided us to less than optimal hyperparameters, asking for and receiving more diverse data likely played a larger role in getting a better model. Still, we would not have come to these realizations if we hadn’t closely examined our data and the ways in which our model was failing.
It’s tempting to think deep learning can just be thrown at a problem and will solve it. This is a concrete reminder that it's essential to understand your data distribution and its limitations, and to take steps to address those when you can. Ultimately, your train/val/test splits are your compass in making and evaluating your models, and without reliable splits, it’s much harder to know where you’re going (I’m pretty proud of this metaphor. I like to think I have the soul of a poet.).
Thanks for reading and I hope all your train and validation splits are uncontaminated!

